QA Automation Tool
Automated Quality Assurance Platform · Built May 2025
Designed, built, and deployed solo at GE HealthCare after mapping the existing manual QA process with the Web Operations team that ran it.
Why I Built It
At GE HealthCare, manual QA testing across the web platform was time-intensive and couldn't keep up with the pace of releases. The Web Operations team needed to know immediately when a page layout broke, a hero banner failed to render, or a critical workflow stopped functioning.
Before building anything, I sat with the Web Operations team to map exactly what they were testing manually and how often, so the tool could replicate every check and then expand on it. I then designed, built, and shipped QAT solo. It runs a comprehensive test suite on a schedule, stores results over time, and surfaces trends so the team can spot regressions early. What used to take several hours of focused manual checking each week now runs unattended every three hours, across a broader set of scenarios than the team had time to cover by hand.
Why build it rather than buy? This was early 2025, before AI-driven QA tools had matured, and procurement would have taken longer than the problem could wait. Manual testing existed because of real user-facing reliability issues, and I wanted to see whether AI could solve them differently while freeing the team to focus on higher-value work. GitHub Actions became the runner mostly because the codebase was already hosted there and I wanted hands-on time with it.
Impact
QAT quietly took a large chunk of routine work off the team's plate, replacing several hours of manual checks each week with unattended runs every three hours.
The project also drew recognition across the marketing organization, including internal peer-nominated rewards and a presentation at the marketing org townhall where the CMO joined the discussion. Colleagues began engaging me as an advisor when they needed to think through how AI could reshape their own workflows. It gave the team a practical model for how automation and AI can free people to focus on higher-value efforts, rather than being presented as an abstract transformation initiative.
based on 3 daily test sessions × 1 hour each × 21 working days
What It Tests
The suite validates real production experiences across hero layouts, navigation, critical UI rendering, and infrastructure responses. For example, TC-01 ensures the hero text and call-to-action remain visible across desktop and mobile viewports on pages like the one shown. When a content change accidentally hides the hero overlay, the next scheduled run catches it before users report it.
- Hero overlay visibility across device sizes
- Page structure and layout integrity
- Navigation and workflow functionality
- Critical UI element rendering
- HTTP status codes and redirects
- Cross-browser responsive design
Runs fire on a schedule every three hours or on demand via the dashboard. A GitHub Actions runner exercises target URLs with Playwright, capturing screenshots on test failures and videos only when explicitly enabled. Structured results go to Supabase Postgres, run summaries to Vercel KV, and media to Vercel Blob. A public copy of summary.json, Excel output, and metadata also publishes to the qat-artifacts GitHub repo so the wider team can view results without authentication. The dashboard reads from the three data stores to surface trends, let the team query results with Gemini, and export reports.
QAT architecture: runs trigger from either a schedule every three hours or an on-demand request from the dashboard form. The Test Runner, implemented as GitHub Actions with Playwright, exercises target URLs such as GE HealthCare pages. Screenshots are captured only on test failures, and videos only when explicitly enabled. The runner writes structured results to Supabase Postgres, run summaries to Vercel KV, and media artifacts to Vercel Blob. A public copy of summary.json, Excel output, and metadata is also published to the qat-artifacts GitHub repository for unauthenticated team access. The dashboard, built with Next.js, reads from Supabase, Vercel KV, and Vercel Blob to render trend charts via Chart.js, AI insights via Gemini and LangChain, and exportable reports via ExcelJS.
Features
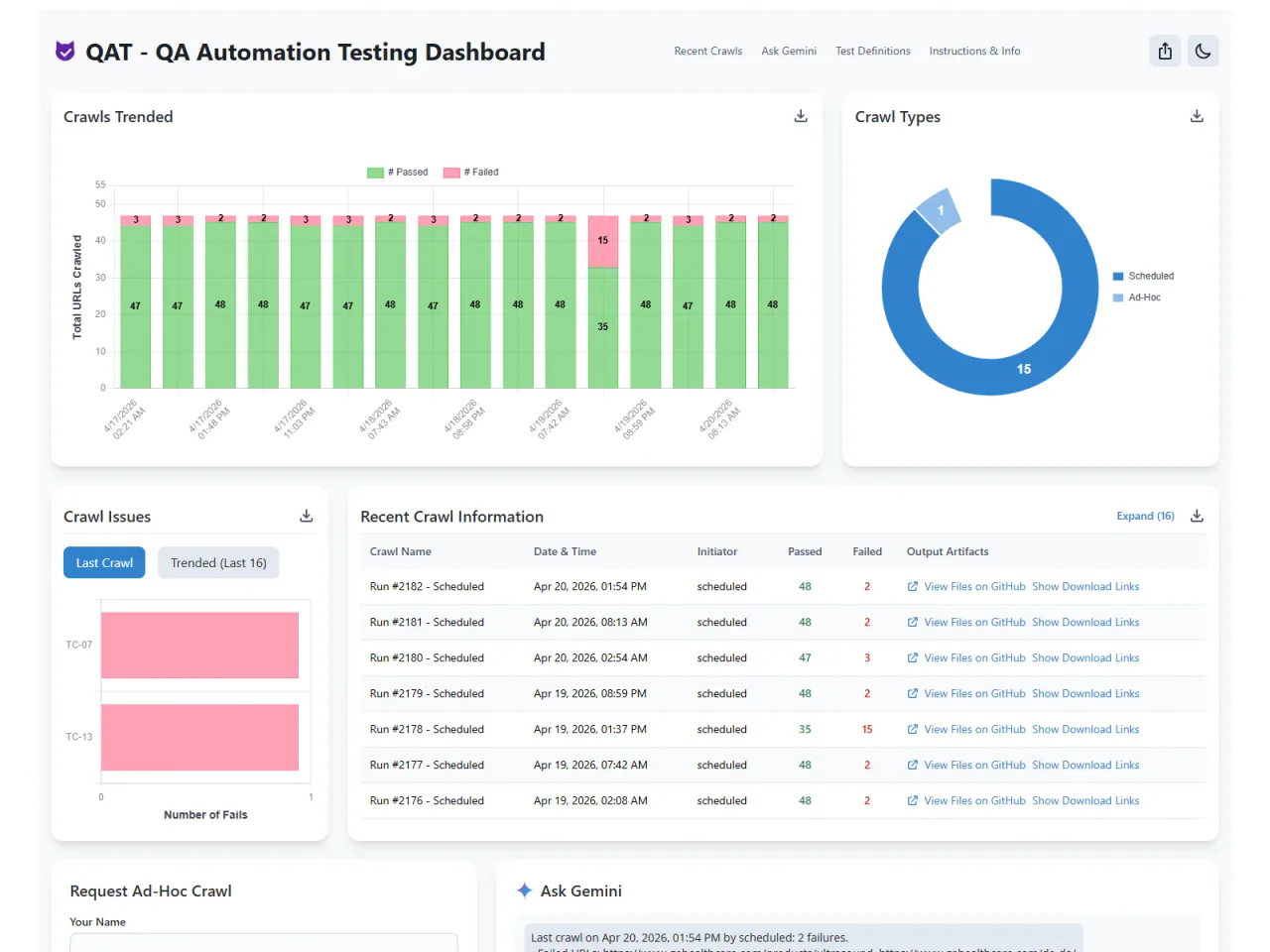
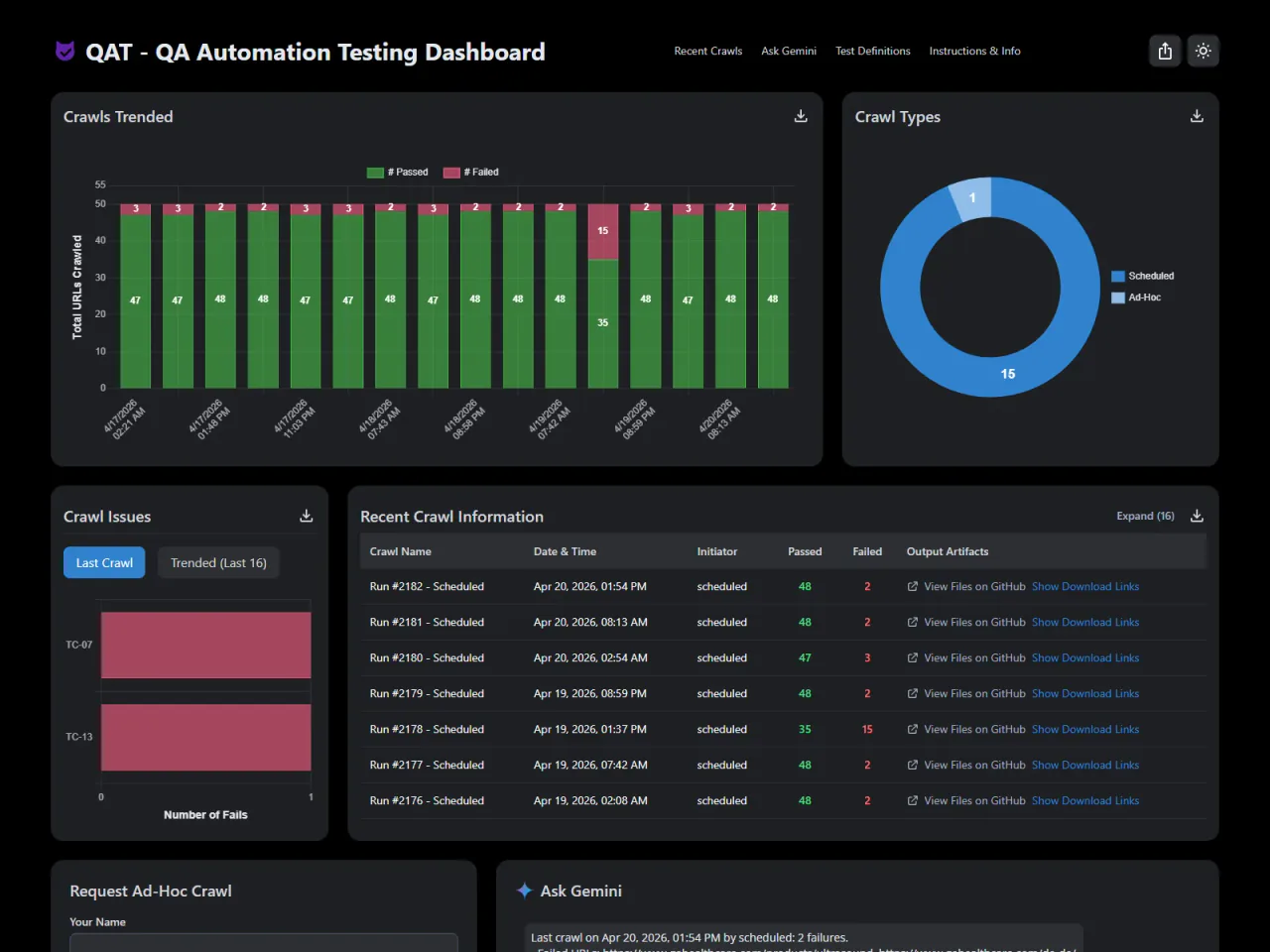
Trend Analysis
Stacked bar chart shows pass versus fail counts for each scheduled and ad-hoc run. Donut chart breaks down the mix of test types. Spot when something breaks and when it was fixed at a glance.
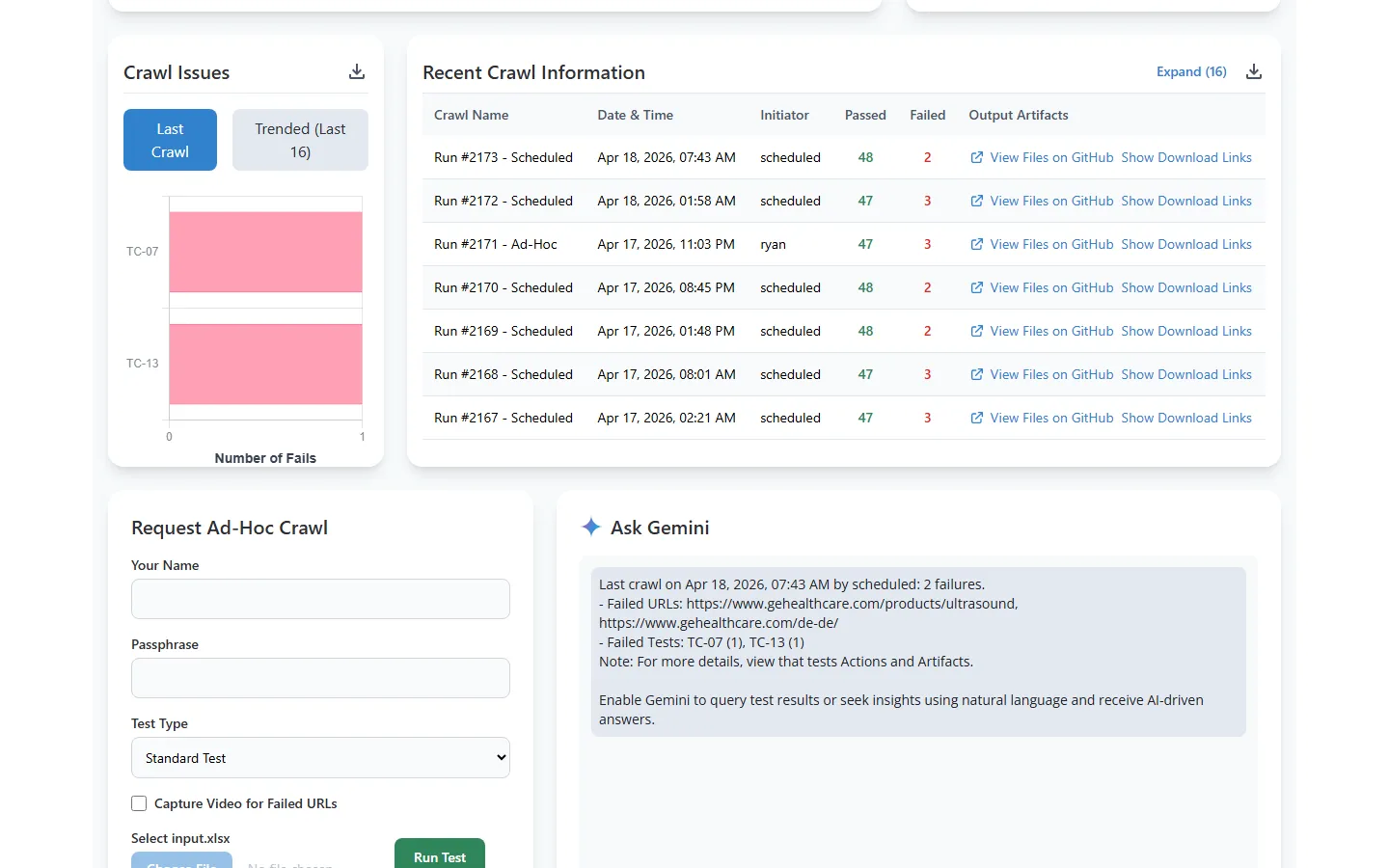
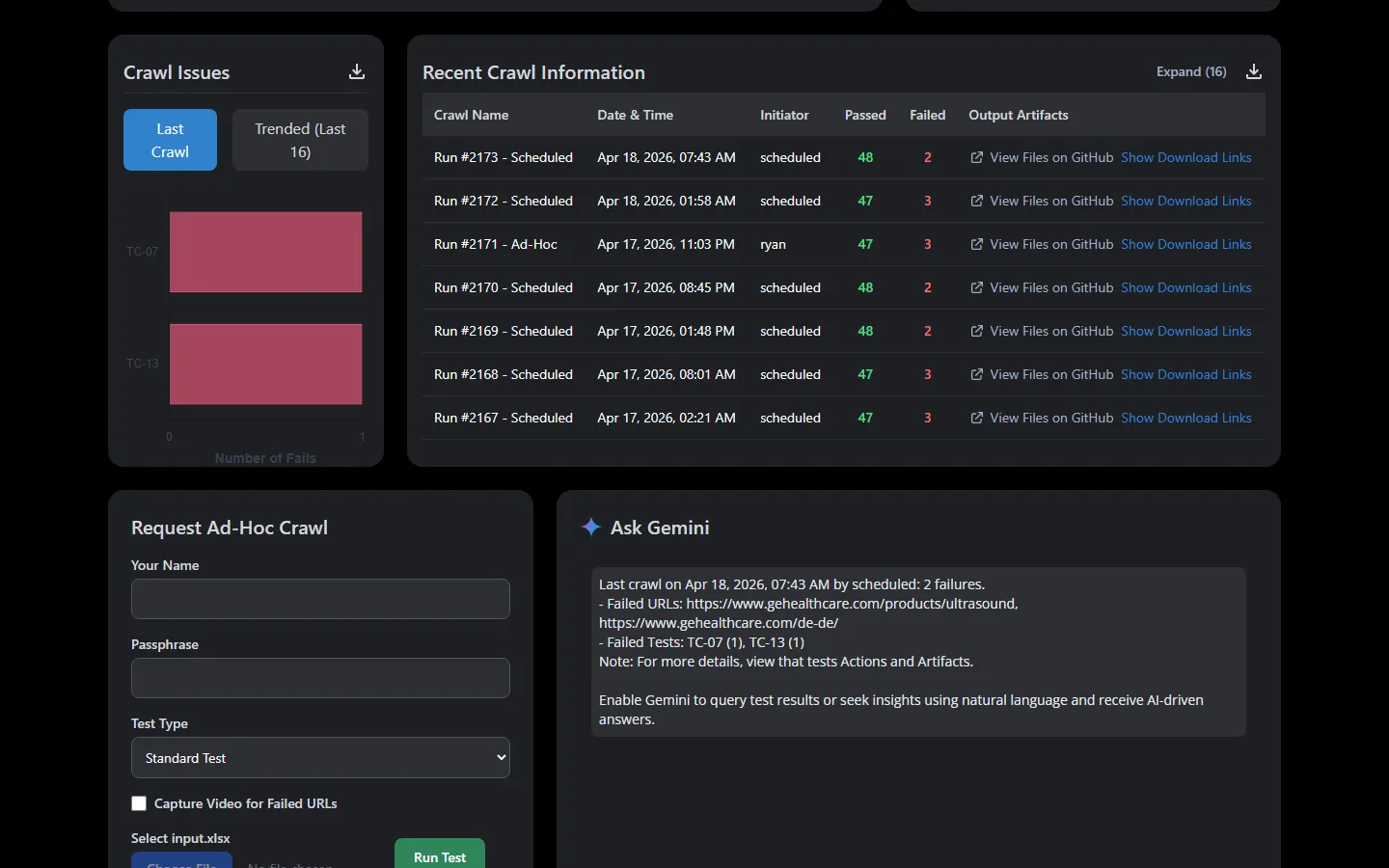
Run History and Artifacts
Every run produces detailed results with pass/fail counts, initiator tracking, and downloadable artifacts. Tests run every 3 hours on a schedule, with the option to trigger ad-hoc runs anytime.
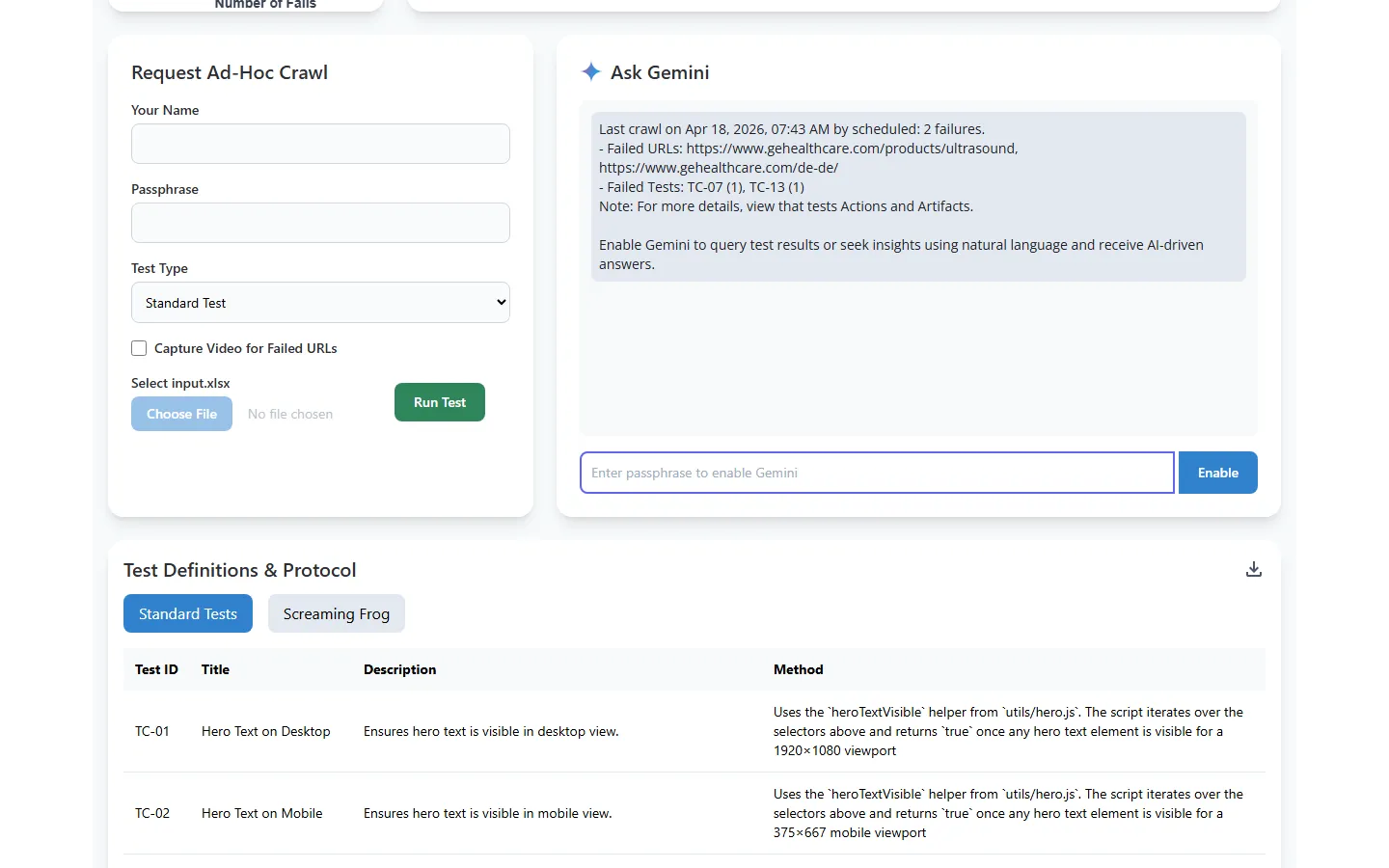
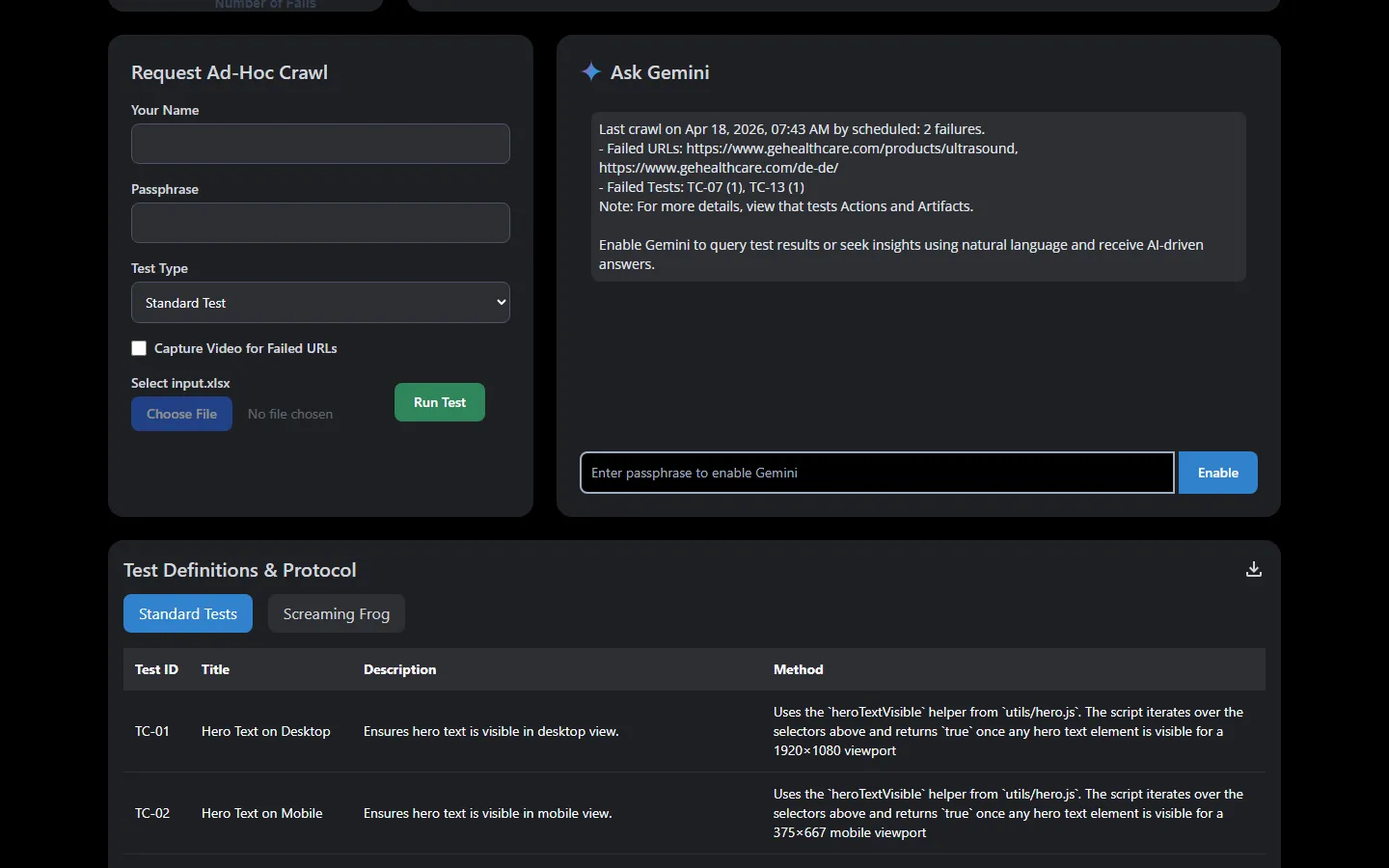
AI Analysis + On-Demand Runs
Ask Gemini natural language questions about your results. Query failure patterns, compare runs, or get summaries. The adjacent ad-hoc form lets team members trigger custom runs without touching the schedule.
Technology
Stack choices reflect what was mature and freely available in early 2025. Gemini and LangChain were among the earliest AI tools with real traction, Supabase was the obvious free-tier database with solid developer experience, and Vercel was an opportunity to get hands-on with a major deploy platform I hadn't used yet.
See It In Action
The live dashboard runs on a public schedule. Browse recent crawls, explore trend data, or dig into the source if you're curious about how it all fits together.
Questions about how this was built, or want to talk about a similar project? LinkedIn Email